Keyword [MAttNet]
Liu X, Wang Z, Shao J, et al. Improving Referring Expression Grounding with Cross-modal Attention-guided Erasing[J]. arXiv preprint arXiv:1903.00839, 2019.
1. Overview
1.1. Motivation
- previous attention models focus on only the most dominant features of both modalities
In this paper, it designs a novel cross-modal attention-guided erasing approach
- generate difficult training samples online
- make full use of latent correspondences between training paris
- avoid overly rely on specific words or visual concepts
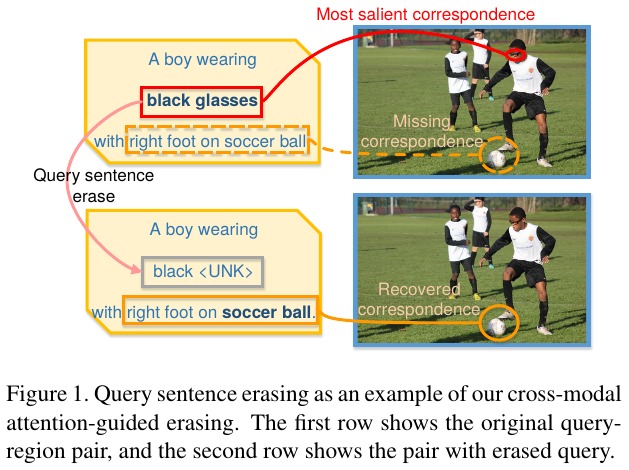
Three types of erasing
- Image-aware query sentence erasing. replace word with unknown token
- Sentence-aware subject region erasing. erase the spatial features
- Sentence-aware context object erasing. erase a dominant context region
1.2. Dataset
- RefCOCO
- RefCOCO+
- RefCOCOg
2. Cross-modal Attention-guided Erasing
2.1. Overview of Attention-guided Erasing
Query Sentence Erasing ($Q^*$).
Visual Erasing ($O^*$).
sample a module based on $Multinominal(3, [w_{subj}, w_{loc}, w_{rel}])$
- subject region erasing on feature maps
- context object erasing to discard features of a context object
Loss Function


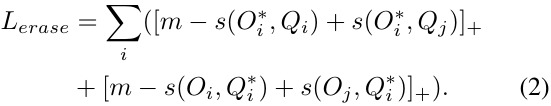
2.2. Image-aware Query Sentence Erasing
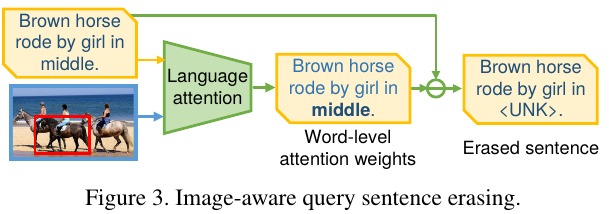
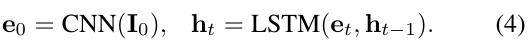
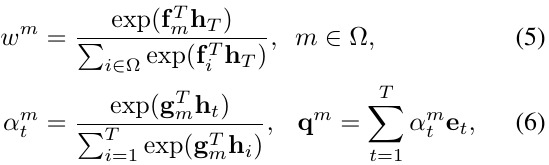

- encode the whole img, then feed into LSTM.
- sample a word from Multinomial(T, [α_1, …, α_T])
2.3. Sentence-aware Subject Region Erasing
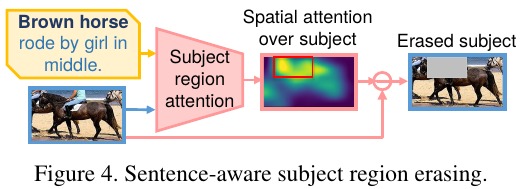
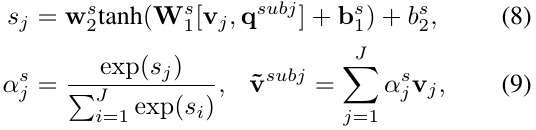
- v_j. a feature point
- erase a continuous region of size kxk (k=3)
2.4. Sentence-aware Context Object Erasing

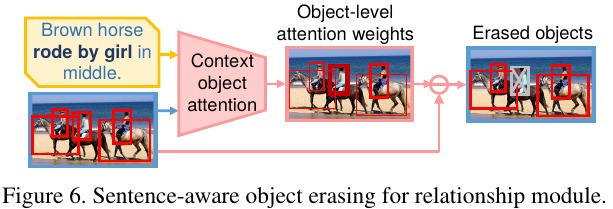

- c_k. context region features
- m = {loc, rel}
Different from MAttNet
- In relationship module, MAttNet assume only one contect object contributes to recognizing the subject
- In this paper, it deals with all context objects and attend to important ones.
Finally, sample a context object based on Multinomial(K, [α_1, …, αK]) and replace its feature to zero.
(already choose which module based on Multinominal(3, [w{subj}, w_{loc}, w_{rel}]))
2.5. Details
- Faster R-CNN with ResNet-101 as backbone to extract image features
- For each candidate object proposal, 7x7 feature maps are fed into subject module